A digital twin is a time-varying representation of a system that brings together observed information and predictive model capabilities. It provides a structure within which to accumulate information and understanding, identify uncertainties and gaps, and reason about the value of new information, in addition to reasoning about potential improvements to system operation.
However, where a Formula 1 racing team might improve performance using a “high-fidelity” digital twin to combine real-time data and computer modeling, digital twins of river catchments and agriculture have to aim to progressively improve understanding over time. We refer to this as the process of digital twinning.
This page describes the design of this digital twin. The design includes this website, and the content of the digital twin has also been used for landholder engagement and policy prompt packs.
The main entry point of this digital twin is the home page.
Digital twin architecture
A key part of a digital twin is the data model within which its elements are stored and accessed. Common industrial digital twins within the Internet of Things (IoT) define interfaces, their properties, components, and telemetry and command endpoints 1. For example, a room can have the property of being occupied or not, and include a thermostat component with telemetered temperature that can also be set.
This digital twin adopts a loosely-coupled integration, in which information sources are kept separate and composed together into a workflow by the analyst. Describing the means of accessing data sources is important but the focus is on human readability over machine readability. Rather than thinking only of IoT “interfaces”, we are interested more generally in “concepts” and their concrete instances, including physical objects, their qualities, processes and events 2.
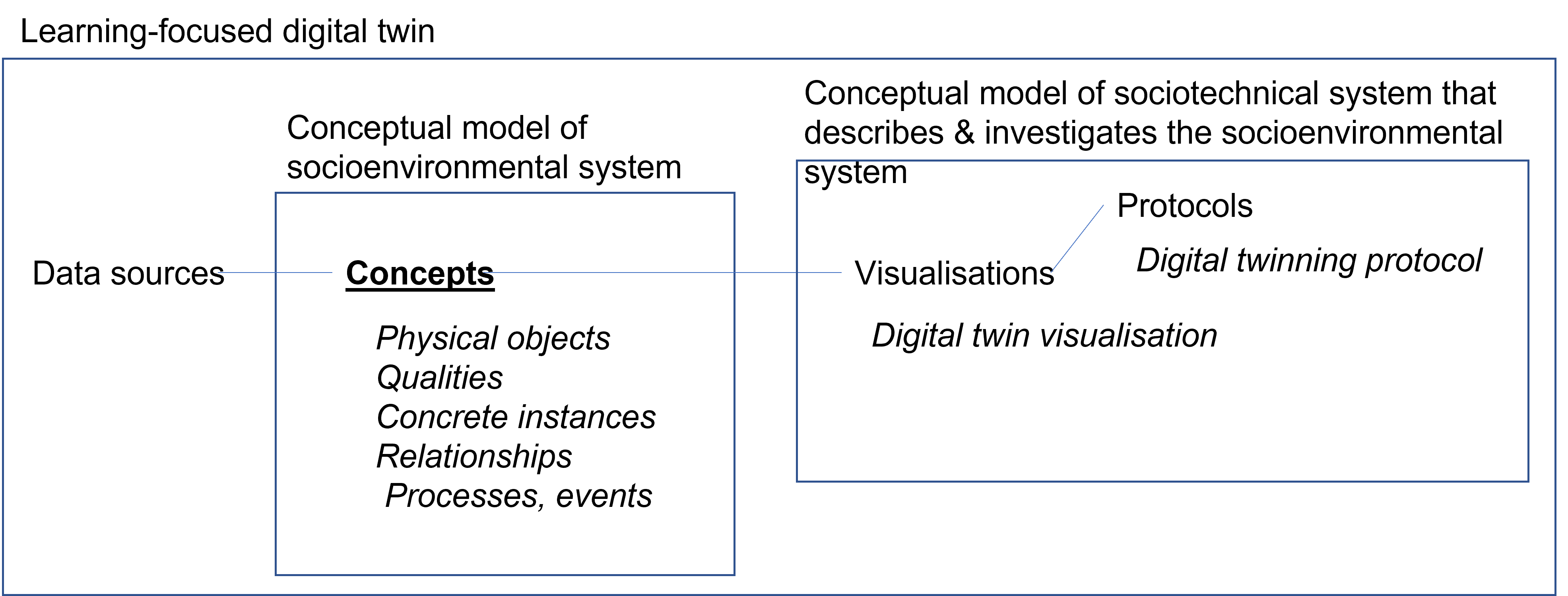
Our data model also includes specific provision to support learning. A conceptual model of the socio-environmental system forms the backbone of the learning-focused digital twin, defining concepts that are within scope of the twin, their concrete instances as well as relationships. Each concept can be linked to zero or more data sources that provide relevant information. The digital twin also includes a conceptual model of the sociotechnical system that describes and investigates the socioenvironmental system. Specifically, protocols describe how visualisations are used in engaging with the digital twin, connecting through to the concepts and data sources involved. The digital twin is itself represented in the conceptual model of the sociotechnical system, with visualisations, and protocols, including a description of the digital twinning process. In addition to the emphasis on progressive improvement of content in the digital twin, this use of self-reference is what gives the digital twin a learning focus.
This digital twin takes the form of a web portal including visualisations in the form of:
- Place-based topic descriptions for elements of the socioenvironmental system, listed under the Gilbert River Agricultural Precinct
- Description of information sharing, the digital twin and its elements (this page), and of the digital twinning process, representing part of the sociotechnical system that describes and investigates the socioenvironmental system.
- Data source descriptions, intended as summaries of information currently available within the sociotechnical system.
The digital twin currently includes two additional protocols, which each implement an engagement driven digital twin:
- Landholder engagement involves use of printed visualisations from the digital twin in conversations about water and water management
- Policy prompt packs involve anonymised cases to facilitate discussion about approval processes
Place-based topic descriptions
The intent of place-based topic description pages is to provide a coherent and complete set of pages on which information about a region (here the Gilbert River Agricultural Precinct) can be stored. Within the scope of the digital twin (currently focused on water), any new piece of information should have a page on which it can be added. The set of pages can change over time, e.g. by splitting a large page when it contains too much information.
The topics of each page correspond to concepts, their concrete instances, and relationships within the digital twin architecture described above. Multiple concepts may be covered on a single page as long as they are consistent with the stated “topic” of the page. Each page is “place-based” in the sense that even when a page talks about a generic concept (e.g. flooding), the focus is on how it applies to the specific region. Content on a particular topic could therefore be adapted from digital twins for other places, but its local relevance would need to be assessed.
Pages are written in narrative form with short paragraphs and supporting images or maps. This format allows qualitative, quantitative, and anecdotal information to be combined. The focus is firstly on providing easy to read content that covers the topic as completely as possible. The text, however, does imply specific assertions about the socio-environmental system and current knowledge about it, which could one day additionally be provided in a machine-readable format.
An index page (Gilbert River Agricultural Precinct) provides a listing of all topics covered in the digital twin, and search functionality helps to find content by keyword. The primary intent, however, is for users to navigate through pages (e.g. from primary entry points listed on the home page) following links between pages on different topics. Similar to Wikipedia, links provide a networked rather than hierarchical relationship between pages, identifying related topics, and allowing more detailed information to be provided on a sub-topic on a separate page.
Handling of scale is a major issue in both water management and this type of page-based website. Two mechanisms are intended here: linking pages across scales, and the potential to link across digital twins. Some concepts, e.g. water availability, span scales, and provide a backbone from which scale-specific pages are linked. For example, water management is a relatively coarse concept, the Gilbert River is spatially specific but relatively large, water bodies refers to a broad class of smaller spatially defined features, farm dams refers to a subclass of water bodies, and the relevance of soils to water management is most relevant at a fairly small scale. The network of concepts allows scales to be bridged conceptually even if currently available data at each scale cannot yet be quantitatively integrated.
While pages can be defined for specific locations, e.g. the proposed Green Hills dam, the website structure is not designed to store arbitrary information at a finer scale. Specifically, it is technically possible but not encouraged to create pages for every property in the region and for every concept as it applies to that property. Assuming property-scale information can be made public, there are two options for its inclusion. If the information is relevant to the scope of the digital twin (water in the GRAP), the first option is to add it to the related topic page, e.g. property-specific observations added to the flooding page. The second option is to include and link to the information in separate property-specific digital twins (e.g. implemented in a property management information system). Given its narrower scope a property-specific digital twin can include more detailed information, and the digital twin at a coarser scale can simply document the existence of this more detailed digital twin. Similarly, this digital twin could cross-link with a digital twin with a larger scope, e.g. on agriculture in the Etheridge Shire, which would include less detail about the Gilbert River Agricultural Precinct specifically.
Data source descriptions
Data source descriptions are intended as summaries of currently available information, including not just datasets, but also models and monitoring and forecasting systems more broadly. Each page describes what the data source consists of, how it was produced, what limitations it might have, and where it can be found. A preview image is provided where appropriate to provide a visual snapshot of what information the data source provides.
Data sources are clearly separated from but linked to the topic(s) they describe. Data source description pages provide links to place-based topic description pages, and limitations are discussed in relation to the ideal coverage of the corresponding topic. The idea is to emphasise that no single data source provides a perfect representation of its topic of interest, existing data should be considered critically as to what it is able to represent, and opportunities to seek improved information should always be on the table.
In the context of loosely-coupled integration, the collection of data source descriptions is intended to provide a user with a list of available information all in one place. The user then still needs to follow up the data sources themselves - the website does not collect or automate access to the data itself. Keeping links to data sources up to date is less demanding than maintaining access to data sources.
In documenting rather than providing data, data source descriptions are somewhat similar to entries in a data catalogue. However, it is perhaps better considered a meta-catalogue - each page includes links to data catalogue entries managed by their respective data custodians and does not repeat the full technical detail available. Additionally, at a meta-catalogue level, data source descriptions comment on limitations and provide previews of data specifically for the region of interest, whereas the original catalogue entry typically describes the characteristics of the dataset as a whole.
Resources
On this website:
- Digital twinning
- Loosely-coupled integration
- Web portal digital twin
- Engagement-driven digital twin
- Self-reference